
Defensive Nixos (1/3) - Intro
Voilà une distribution que l’on peut encore qualifier de « niche ». Pourtant, NixOS (et les quelques projets plus modestes du même acabit) fait de plus en plus parler de lui. Il est possible que vous ayez déjà vu passer le nom de cette distribution Linux au détour d’un commentaire Hacker News ou d’une discussion avec un collègue un peu farfelu. (Vous savez ce libriste insuportable qui vous reprend toujours sur la définition “d’open source” et de “DevOps” et qui installe un nouvel OS tous les week-end).
NixOS est mon outil de travail principal depuis 3 ans. Malgré son jeune âge (première version utilisable autour de 2013), ses avantages en termes de robustesse, de maintenabilité et de sécurité sont, à mon avis, inégalés.
Beaucoup d’organismes gagneraient à déployer ce type de technologies à grande échelle. C’est la raison pour laquelle je démarre une petite série d’articles sur le sujet. Même sans parler d’un changement complet d’infrastructure, il me semble que le principe de déploiement fonctionnel dont nous allons parler est une excellente source d’inspiration pour ceux qui travaillent dans le développement et la maintenance d’infrastructures.
Les premiers articles se contenteront principalement de revenir sur ce que j’ai déjà présenté dans ma conférence sur le sujet à la Hack’it’N de 2022.
Bien sûr, expliquer le fonctionnement détaillé de NixOS dans une poignée d’articles n’est pas envisageable. D’autant qu’il existe déjà les excellents Nix Pills. Ces articles, écrits par l’un des principaux contributeurs de la communauté NixOS, sont d’une rare qualité et constituent la porte d’entrée privilégiée vers les entrailles de la bête.
Mon objectif est un peu différent. Avec ces articles, je veux m’adresser aux blue teams, ops, secops, devsecops, RSSI et autres noms compliqués pour : ingénieur en sécurité informatique. NixOS, et la philosophie everything-as-code qui l’a engendré, sont, j’en suis persuadé, les briques et le mortier des cyber-forteresses de demain.
Je vous propose donc de me suivre dans cette découverte de NixOS et de ses avantages en termes de sécurité informatique.
Challenges techniques
Avant de présenter la technologie, je veux commencer par introduire un certain nombre de problèmes qui, je pense, vont parler à beaucoup d’entre vous. Ces problèmes sont à l’origine de nombreux incidents de sécurité (ou y ont au moins fortement contribué) au point que des jobs à part entière ont été créés pour les résoudre.
Inexhaustivité de la cartographie : c’est, pour moi, le point le plus central. Les systèmes d’information modernes ne cessent de se complexifier. La visibilité des équipes d’administration sur leurs infrastructures est souvent très médiocre. Il est difficile de dire quelles machines sont déployées, dans quel DC, et ce qui est installé dessus. C’est un vrai problème pour la maintenabilité des parcs informatiques et, par conséquent, pour la sécurité des réseaux.
Entropie des configurations : en plus de l’absence de traçabilité sur les configurations, il est également très difficile de trouver des standards.
Dans les systèmes d’information les plus anciens que j’ai pu voir, il y avait généralement autant de pratiques de configuration que de déploiements différents.
Chaque administrateur a ses habitudes et préférences.
Une même application peut être déployée un jour avec un paquet pip et le lendemain par l’extraction d’une archive dans /opt.
Que ce soit pour la maintenabilité ou la réponse aux incidents, sans normalisation, le métier d’ops devient vite un enfer.
Gestion chaotique des patchs : comme les configurations sont chaotiques, appliquer un patch de sécurité peut vite devenir une tâche herculéenne. Même lorsque l’application du patch est simple, le manque de visibilité empêche d’avoir la moindre certitude quant à sa robustesse. Chaque mise en production d’infrastructure s’accompagne généralement d’une peur bleue : tomber sur des incompatibilités qui n’avaient pas été découvertes en pré-production.
Obscurité à l’audit : je le constate dans mon activité actuelle, auditer un système est souvent plus compliqué qu’il ne devrait l’être. Cela se résume généralement à trois méthodes : commenter un schéma d’architecture qui n’est souvent plus à jour ; analyser une poignée de fichiers de configuration (hors contexte et qui ne sont pas représentatifs de la majorité de l’infrastructure) ; ou réaliser des exercices de pentest qui ne sont pas du tout exhaustifs.
Automatisation complexe : il est facile de sauvegarder le contenu d’une base de données ou le code source d’une application pour les restaurer en cas d’incident. Il est plus difficile de restaurer une infrastructure entière avec ses machines virtuelles, leurs systèmes de fichiers et leur configuration exacte. Les procédures de déploiement, qui sont censées être le garde-fou dans ce genre de scénario, sont souvent réputées incomplètes ou obsolètes.
Etat de l’art
En général, les premières tentatives d’automatisation et de standardisation “as code” de l’infra se font à l’aide de scripts et/ou de GPO. Cette solution est évidemment très peu robuste et, même si elle est facile à mettre en place pour de petits réseaux, elle est loin d’être scalable. Bien souvent, les scripts sont transférés via des clés USB, par mail ou stockés sur un partage réseau (j’entends des RSSI tousser). La gestion des versions est presque inexistante, et les tentatives de normalisation sont vouées à l’échec.
Une fois que le réseau grossit, que les équipes gagnent en maturité (et qu’une ou un DSI décide de bien vouloir allouer du budget), on voit apparaître de l’infra as code. La mise en place de l’IaC peut parfois être très tâtonnante, mais c’est généralement un grand pas vers la résilience informatique. Cependant, peu importe les technologies utilisée (Ansible, Terraform, SaltStack, …), elles se basent sur un état virtuel du système. La moindre modification manuelle d’un admin qui ne serait pas reportée dans le code peut entraîner des heures, voire des jours de débogage. Ceux qui ont déjà écrit des recettes Ansible savent qu’une grande partie (parfois la majorité) du temps peut être consacrée à rendre ces recettes idempotentes.
Enfin, il y a les conteneurs. Bien sûr, cette technologie résout beaucoup des problèmes dont nous avons parlé plus haut. Cependant, cette solution n’est pas applicable partout, en particulier lorsqu’il s’agit de maintenir des infrastructures physiques.
Le système parfait
Bien, énumérons humblement les caractéristiques d’un système d’infrastructure as code parfait d’après ce que nous avons vu :
- Automatisable : une toolchain facile à manipuler doit permettre d’automatiser l’installation d’un système avec précision, sans intervention humaine.
- Versionnable : il doit être possible de versionner entièrement la configuration du système (en plus des snapshots, qui ne devraient s’intéresser qu’aux données).
- Auditable : la lecture du fichier de code/configuration ne doit laisser aucun doute quant à la configuration exacte du système tel qu’il est déployé.
- Full-Feature : toutes les fonctionnalités d’un système d’automatisation classique (e.g. ansible) doivent être présentes.
- Reproductible & idempotent : les mises à jour et/ou redéploiements doivent être déterministes et strictement idempotents.
Conceptes de base
Nix Package Manager : Dérivation > Package
Tout commence en 2006 avec une publication d’Eelco Dolstra.

Il y présente les principaux problèmes des gestionnaires de paquets traditionnels, en particulier la difficulté croissante à gérer les dépendances (cf. dépendances cycliques) et la sensibilité aux changements cassants. Pour y répondre, il propose un nouveau modèle inspiré des langages fonctionnels.
Dans son modèle, les paquets doivent posséder les mêmes propriétés que celles que l’on retrouve en programmation fonctionnelle :
- Immutabilité : une fois installé, il n’est pas possible de modifier un package.
- Isolation : comme pour les fonctions, l’installation d’un package ne doit pas pouvoir impacter l’exécution des autres.
- Déterminisme : toutes les dépendances sont identifiées de façon exhaustive, les installations doivent êtres idempotentes.
On appelle un paquet possédant ces propriétés une dérivation.

Cela change profondément l’approche traditionnelle de l’administration système. Avec tout le respect que je dois à la distribution Debian et à tout ce qu’elle a apporté au monde de l’open source, dpkg est un enfer à manipuler. Son historique ne lui rend pas service.
Grâce au principe de dérivation, oubliez les packages obscurs qui mélangent systèmes de build inconnus, scripts ésotériques et variables d’environnement mystiques. Les définitions de dérivations sont écrites dans une syntaxe claire et accessibles même aux novices.
Nix Store
Pour continuer sur le parallèle avec Debian, prenez un .deb.
Une fois installé, le paquet dépose un tas de fichiers partout dans le système
(binaires dans /usr/bin, bibliothèques dans /var/lib, …).
Même s’il y a un semblant d’ordre et que des outils ont été créés pour faciliter la gestion, il reste fastidieux de savoir exactement quel paquet est à l’origine de tel fichier
(sans parler des conflits lorsque deux paquets veulent écraser le même fichier).
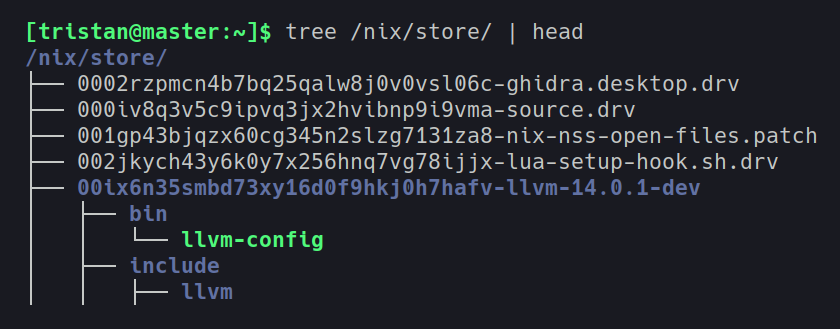
Avec NixOS, plus besoin de chercher où sont les fichiers et à qui ils appartiennent.
Tout (ou presque) est stocké dans /nix/store (comme dans l’exemple ci-dessus avec LLVM).
Ici, chaque dérivation est représentée par un hash.
Pour simplifier, ce hash est la concaténation de toutes les sources nécessaires à la construction du paquet et des hashes de toutes les dérivations dont il dépend.
HASH_DERIVATION ~= hash( hash(SOURCES) + hash(DEPENDANCES) )
Ce fonctionnement permet de garantir l’intégrité et l’immutabilité totale de tous les paquets et de leurs dépendances, jusqu’aux briques les plus élémentaires (un peu à la manière d’une chaîne de blocs pour les crypto-addicts). On peut également oublier les problèmes de collision de noms, que ce soit par accident (deux paquets ayant le même nom) ou à cause d’un attaquant qui cherche à s’amuser avec du path hijacking et autres joyeusetés.
Faire le lien
Pour clarifier le fonctionnement du Nix store, prenons un exemple précis. Sur ma machine, j’ai GCC d’installé.
[tristan@demo:~]$ gcc --version
gcc (GCC) 11.3.0
Pour faire tourner GCC, mon shell a cherché le binaire dans le PATH et l’a trouvé dans un dossier .nix-profile dans mon répertoire personnel.
[tristan@demo:~]$ which gcc
/home/tristan/.nix-profile/bin/gcc
Ce fichier n’est qu’un lien vers le Nix store, qui contient réellement le binaire. Tout cet enchaînement est instancié au démarrage pour chaque utilisateur, en fonction des binaires auxquels il est censé accéder.
[tristan@demo:~]$ ls -l /home/tristan/.nix-profile/bin/gcc
/home/tristan/.nix-profile/bin/gcc -> /nix/store/ykcrnkiicqg1pwls9kgnmf0hd9qjqp4x-gcc-wrapper-11.3.0/bin/gcc
Poussons maintenant l’investigation encore plus loin pour voir le contenu de ce fichier GCC. (Le milieu du fichier est volontairement censuré car le fichier est très long et complexe.)
#! /nix/store/c24i2kds9yzzjjik6qdnjg7a94i9pp05-bash-5.2-p15/bin/bash
set -eu -o pipefail +o posix
shopt -s nullglob
if (( "${NIX_DEBUG:-0}" >= 7 )); then
set -x
fi
path_backup="$PATH"
source /nix/store/zd2viirgdm4ffgipgpslmysmlzs6fscb-gcc-wrapper-12.3.0/nix-support/utils.bash
[...]
# if a cc-wrapper-hook exists, run it.
if [[ -e /nix/store/zd2viirgdm4ffgipgpslmysmlzs6fscb-gcc-wrapper-12.3.0/nix-support/cc-wrapper-hook ]]; then
compiler=/nix/store/dfqlrp0zgq8k21qajn7z6d0yjn9ab9af-gcc-12.3.0/bin/gcc
source /nix/store/zd2viirgdm4ffgipgpslmysmlzs6fscb-gcc-wrapper-12.3.0/nix-support/cc-wrapper-hook
fi
if (( "${NIX_CC_USE_RESPONSE_FILE:-0}" >= 1 )); then
responseFile=$(mktemp "${TMPDIR:-/tmp}/cc-params.XXXXXX")
trap 'rm -f -- "$responseFile"' EXIT
printf "%q\n" \
${extraBefore+"${extraBefore[@]}"} \
${params+"${params[@]}"} \
${extraAfter+"${extraAfter[@]}"} > "$responseFile"
/nix/store/dfqlrp0zgq8k21qajn7z6d0yjn9ab9af-gcc-12.3.0/bin/gcc "@$responseFile"
else
exec /nix/store/dfqlrp0zgq8k21qajn7z6d0yjn9ab9af-gcc-12.3.0/bin/gcc \
${extraBefore+"${extraBefore[@]}"} \
${params+"${params[@]}"} \
${extraAfter+"${extraAfter[@]}"}
fi
La première chose que l’on peut remarquer, c’est qu’il ne s’agit toujours pas du binaire GCC à proprement parler, mais d’un wrapper Bash. Ce wrapper a pour rôle de préparer l’environnement d’exécution de GCC en lui fournissant toutes les bibliothèques, outils et scripts nécessaires directement depuis le nix-store.
Le deuxième élément important, c’est la présence de chemins absolus pour toutes les commandes utilisées.
C’est grâce à ce mécanisme que chaque dépendance est identifiée et qu’aucune résolution de chemin n’est laissée au hasard ou à des conventions floues.
En gros, chez NixOS, c’est configuration over convention, et c’est très bien.
Bien évidemment, un tel script est difficilement lisible et n’est jamais rédigé à la main. Nous verrons dans un prochain article comment le code Nix d’origine est structuré pour permettre de générer ce type de fichier.
Mirroir mon gros mirroir
Nous l’avons vu plus tôt, l’équivalent d’un paquet dans l’univers Nix est la dérivation. Bien évidemment, une dérivation ne ressemble pas du tout à un paquet. Un problème courant des distributions qui adoptent un nouveau gestionnaire de paquets est la difficulté de recréer une bibliothèque de paquets suffisamment exhaustive. La raison : le besoin de repackager tous les programmes, de monter une infrastructure complète pour les miroirs, et de mettre en place un processus de Q&A (protection et versionnement des branches LTS / stable / testing / unstable / …).
La grande force de NixOS, plus encore que ce qui a été évoqué précédemment, c’est le langage déclaratif et fonctionnel sur lequel Nix est construit. Ce langage fonctionnel s’appelle… Nix… comme le gestionnaire de paquets (un choix critiquable, certes, mais si les développeurs étaient poètes, ça se saurait). Cependant, la simplicité et l’élégance de ce langage ont permis de simplifier l’écriture des dérivations de manière remarquable, au point que le problème de re-packaging s’est résolu avec une rapidité surprenante.
NixOS est aujourd’hui la distribution qui propose le plus grand nombre de paquets différents (plus de 100 000 à l’heure où j’écris).
Et pour régler le problème de l’infrastructure, vu que tout est défini dans le même langage de programmation, pas besoin de miroir dédié. Le miroir de NixOS, c’est tout simplement le dépôt nixpkgs sur GitHub.
Les plus avisés auront remarqué la quantité très impressionnante d’issues et de pull requests du projet. En effet, c’est un symptôme de la simplicité de développement, mais aussi du succès et de l’intérêt que la distribution suscite. Si le projet vous intéresse, contribuez, c’est le meilleur moyen d’apprendre !
Système As Code
On l’a vu, tous les paquets sont écrits dans le même langage fonctionnel.
Mais ce n’est pas tout. Sur NixOS, c’est tout le système qui peut être représenté en Nix.
Ce principe de system as code est probablement ce qui attire en priorité les gens vers la distrib.
Mais je ne m’étendrai pas sur la syntaxe de Nix aujourd’hui, ce sera le sujet du prochain article !